
都度登録される履歴書とのマッチングを人力で対応
商社であるR社は2000人もの社員がいますが、人手不足から、通年で中途社員の採用活動を行っています。募集職種と求人者が多いために独自のデータベースで履歴書など採用に関するデータを管理していますが、書類の確認作業などは全て人の手で行っているため、管理が煩雑化し、手間がかかってしまっていました。毎日10件以上の履歴書が登録され、その確認だけでも時間がかかり、求職者が多い時期には負担が増え残業も多く発生し、人件費の増加と現場の社員からの不満が高まっていました。
また、R社はポテンシャル採用を行っており、登録した履歴書はR社だけでなくグループ会社へも紹介を行っています。グループ全体で募集している職種は50種類を超え、更にポテンシャル採用も行っているため、現場とのマッチングが欠かせません。しかし実務が担当者のノウハウに依存している状況であったため、マッチング精度をあげることも経営陣から求められていました。
システム管理部のTさんは、採用ステップの中で履歴書の確認のコスト削減と現場とのマッチング精度の向上を課題として取り上げ、知り合いのデータサイエンティストに相談することにしました。
求人票のマッチング精度を機械学習で向上させる2つのポイント
データサイエンティストがヒアリングを行った結果、履歴書から採用確率の高い履歴書を推薦するシステムを開発することは可能だと考えました。初期分析、モデル作成、開発の3つのフェーズに分けてのシステム開発をR社に提案し、進めることになりました。
構文解析サービスで求人に関する約5万語を分析
まずは構文解析サービスで、求人において頻出する単語を抽出しました。
職種や募集要項を満たす単語、あるいは関連性の深い単語を洗い出し、単語同士の関係の深さをベクトルで示しました。例えば、自己アピール欄に「集中力」と書いている人がエンジニアに採用される確率が高ければ、単語ベクトルは短く、単語同士の関係性が近いということになります。採用/不採用だった場合の履歴書/求人票から、求人に関する約5万語についてそれぞれ関係性を単語ベクトルに変換しました。
選考ステップに基づいた重み付け
次に、作成した単語ベクトルをもとに、選考のステータススコアを設定しました。
このデータを利用することで採用/不採用だけでなく、選考過程のうち、どこで不採用とされたのかのデータを用いることで、選考通過に必要な要素の抽出が可能となります。
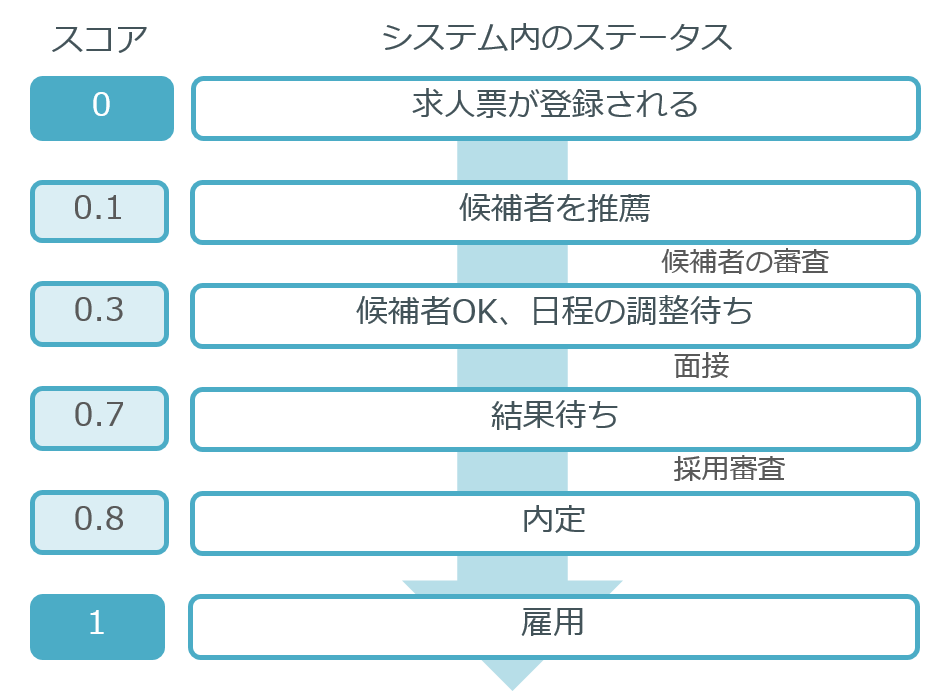
求人票登録を0、雇用を1として、各過程にスコアをわりあてて、重み付けを行いました。
採用確率の高い候補者を推薦するシステムの開発
求人票のマッチング精度を機械学習で向上させる2つのポイントを設定し、その分析をもとに履歴書と求人票を照らし合わせた時に採用確率を示すシステムの開発を行いました。
一ヶ月検証を行ったところ、求人票に対する候補者の採用確率の表示システムにより、求人票確認やマッチングする時間が1/3に減り、工数を削減することもできました。現場の希望との合致の精度も上がり、より希望する人材の採用が可能となりました。
採用に必要なスキルを推薦するシステムの開発
今後は、データを蓄積することでシステムの採用確率の精度をさらに高めるとともに、採用過程など、関連情報を採用関係者が閲覧できるようなシステムを開発する予定です。
導入後の効果
- 履歴書確認、マッチング作業の時間短縮につながり、業務に余裕が生まれるようになった
- 担当者の感覚で行っていたマッチングを数値で示すことでより精度を向上させることができた
AIや機械学習によるビッグデータ活用をしたい方にオススメ!

「AIによるキャスト評価システムの構築」「データ分析基盤の運用費用9割削減」など、AWSを利用したAI、機械学習のの成功事例をご紹介します。