
AWSへの移行後の設計と運用のポイントを解説する「AWSに移行した環境の最適化のススメ」の連載です。前回の「AWSへの最適化の考え方」では、AWSを最大限に活用するための重要なポイントをご紹介しました。
今回の「事例と構成例」では、本連載でご紹介したことを踏まえて、どのように最適化を進めていくのか具体例とともに解説します。
連載「AWSに移行した環境の最適化のススメ」
【1】 AWSへの移行と障害時の対応
【2】 AWSへの最適化の考え方
▶【3】 事例と構成例
事例1 Webアプリケーションのバックエンドの冗長化
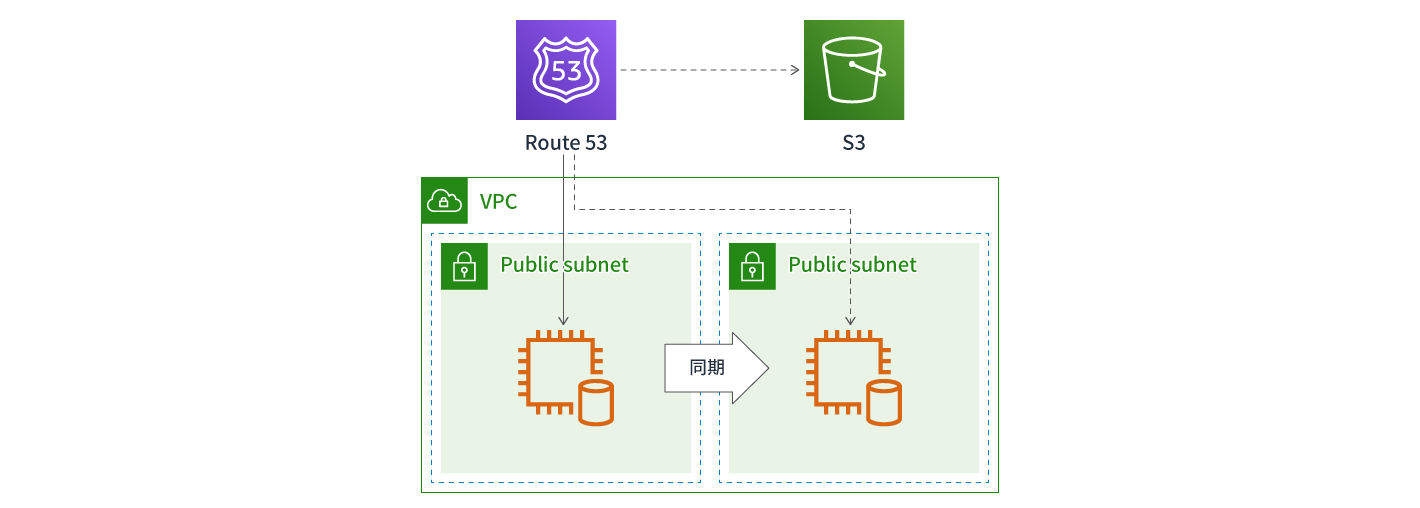
リフト時の状況
ユーザーが自身で撮影した写真をアップロードしてシェアするWebアプリケーションをオンプレミスで運用していたA社。Active/Standbyの2台構成のLAMP環境をそのままAWSにリフトしました。Activeが応答しない場合、AWSが提供しているDNSであるAmazon Route53のヘルスチェックをトリガーに、S3上にあるSorryページに復帰先を自動で切り替えるような構成にしています。ちなみにS3はオブジェクトストレージサービスですが、静的なウェブサイトをホスティング出来る機能があります。
ActiveからStandbyへは、lsyncとrsyncを利用しコンテンツを同期しています。データベースはMySQLのMaster/Slave構成となっており、基本的にはActive/Standbyに同じものが載っている状態です。Activeが完全に落ちてしまった場合は、StandbyのMySQLをMasterへ昇格し、DNSをStandby側に手動で切り替えるという運用を行っています。
また、ユーザー数の増加に伴いリソースが枯渇した際は、メンテナンス時間を設けて手動でスケールアップを行っています。
ビジネス要件の変化と課題
ユーザー数の増加に伴い、サーバーリソースが枯渇しSorryページの表示が頻発するようになりました。そのたびにスケールアップのメンテナンスが発生するため、社内からメンテナンス時間を設けずにユーザー数増加に対応したいという要望が出てきました。
実は、リフト時点でもElastic Load Balancing (ELB)・EC2・RDSを利用した構成への変更を検討していましたが、ユーザーからアップロードされた画像ファイルを2台のEC2間で共有する最適な方法が見つからず、断念していました。画像ファイルをS3に格納する案も挙がりましたが、レイテンシーやアプリケーション自体の改修がボトルネックとなり、採用は難しいと判断しました。他にもNFSサーバーを立てる案がありましたが、NFSサーバーが単一障害点となってしまうため、こちらの案も不採用となりました。
最適化の方法
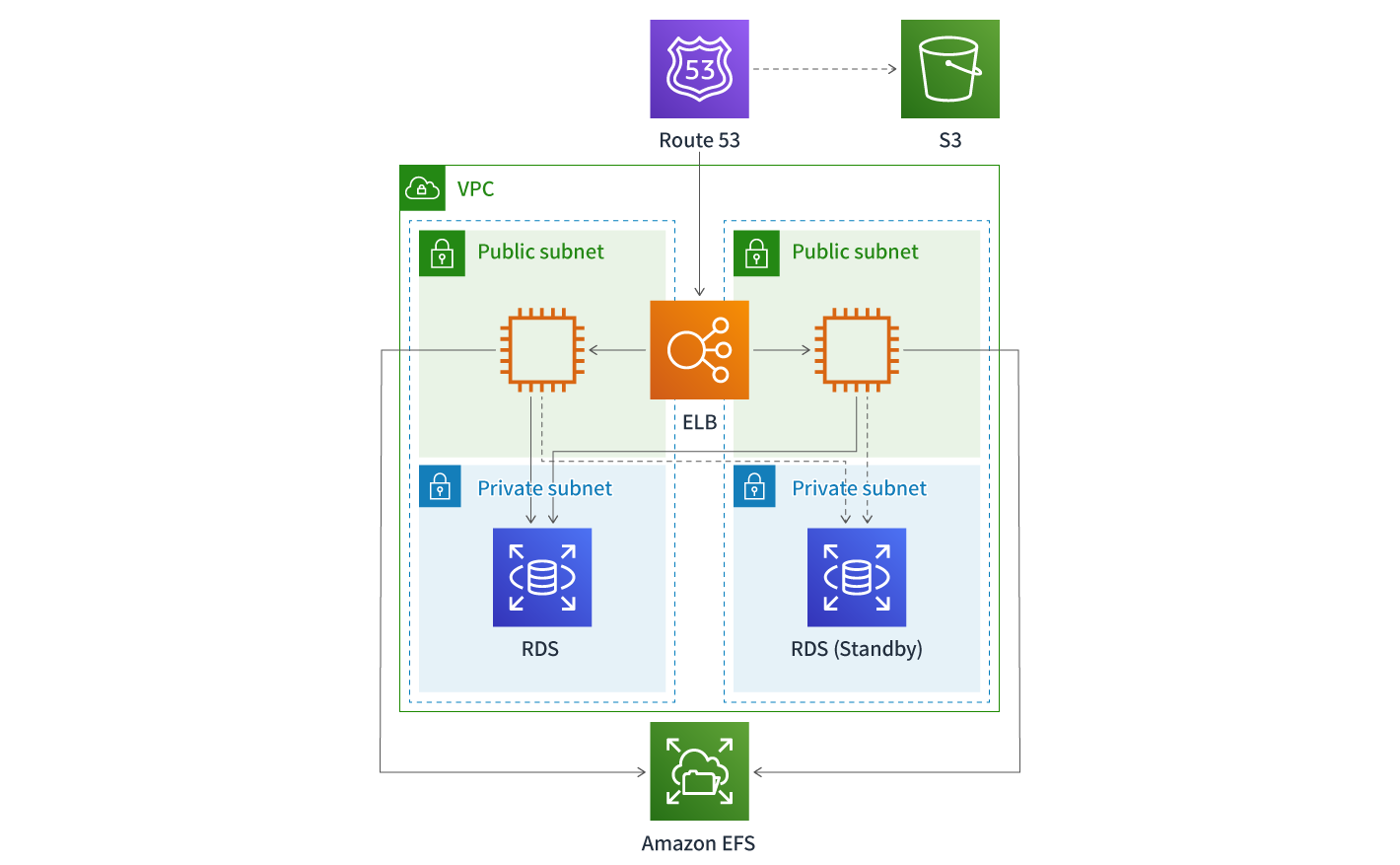
Amazon Elastic File System(EFS)を利用し可用性を向上
まず、Amazon Elastic File System(Amazon EFS)というサービスの導入を行いました。Amazon EFSはマネージド型の共有ファイルストレージサービスであり、NFSv4に対応しています。2018年7月に東京リージョンでも利用可能となりました。ストレージ容量は自動で拡張し、スループットやIOPSもファイルシステムの拡張に併せてスケールします。Amazon EFSに保存されたファイルは複数のアベイラビリティーゾーンに複製されるためファイル消失の可能性は極めて低いです。Amazon EFSの導入によって2台のEC2間のファイル共有の課題を解決することができました。
残課題と今後のシフト
Amazon EFSのスループットは先に記載した通り、自動でスケールしますが、格納されているファイルの合計容量が少ないとスループットが上がらないままとなってしまいます。このため、軽量なログインセッションファイルをAmazon EFSに置いてしまうとログイン速度が遅くなる問題が発生しました。ELBのセッション維持機能を使うことで2台のEC2間のログインセッション共有の課題を回避しましたが、これだとセッションの偏りが発生する場合があります。そのため、今後はアプリケーションを改修し、RedisとMemcachedに対応したマネージド型のインメモリデータストアであるAmazon ElastiCacheにセッション管理を移行し、2台でセッションを共有する構成にすることを検討しています。また、急なアクセス増加に対応するために、Amazon CloudFrontとAuto Scalingの導入も行う予定です。
事例2 コーポレートサイトと会員サイトの統合
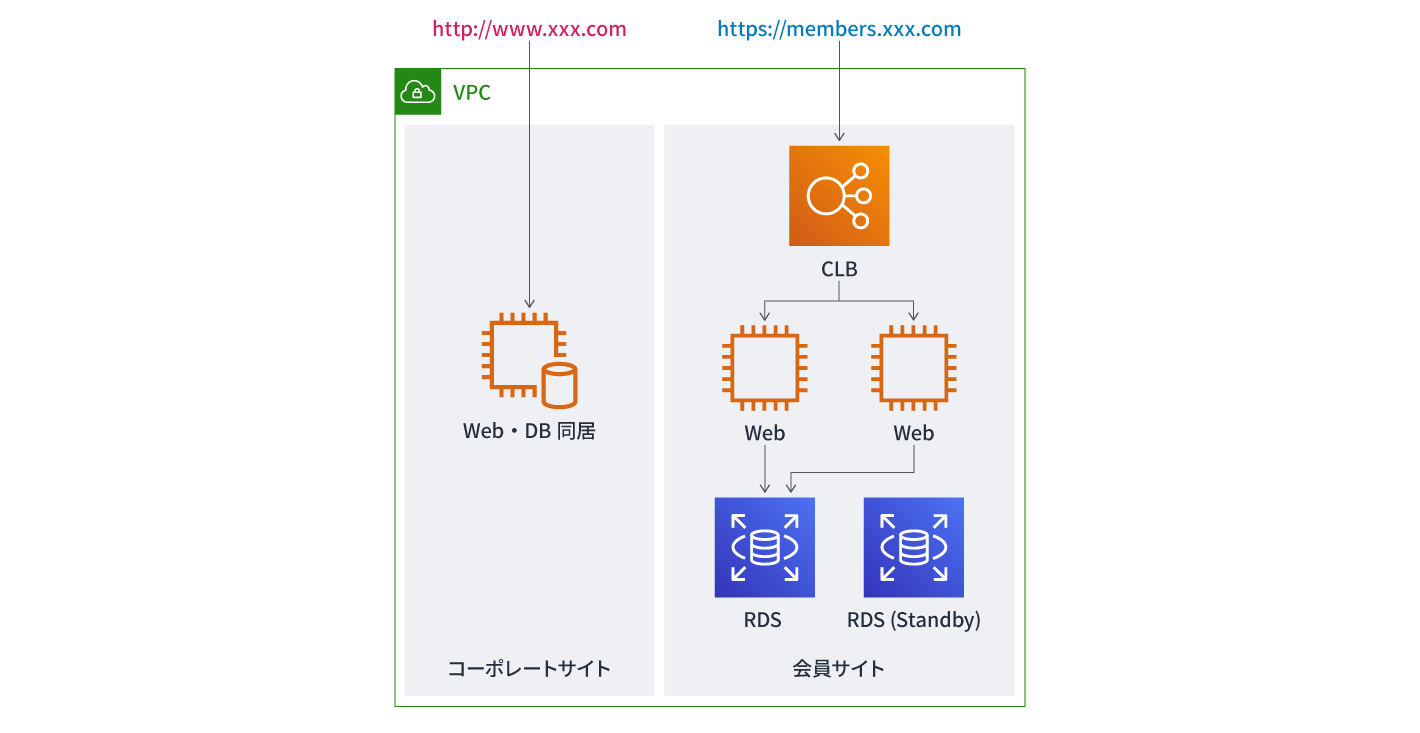
リフト時の状況
コーポレートサイトと会員サイトの2サイトを運営しているB社。コーポレートサイトは1台構成のオンプレミス環境からAWSへリフトし、EC2シングルインスタンスで稼働しています。会員サイトは、AWS上に新規構築したため、Classic Load Balancer(CLB)・EC2・RDSのLAMP環境で、複数のアベイラビリティーゾーンを利用した冗長構成になっています。会員サイトはSSL化されていますが、コーポレートサイトはSSL化が出来ていない状況です。
ビジネス要件の変化と課題
ブランディング戦略の一環として、コーポレートサイトと会員サイトを同一ドメインかつ全ページSSL化にしたいという要望が社内から出てきました。しかし、コーポレートサイトは複数の制作会社に外注していた経緯があり、リダイレクトルールがバラバラでブラックボックス化しています。そのためHTTPからHTTPSへのリダイレクトは、このリダイレクトルールを整理しなければ出来ない状況となっていました。
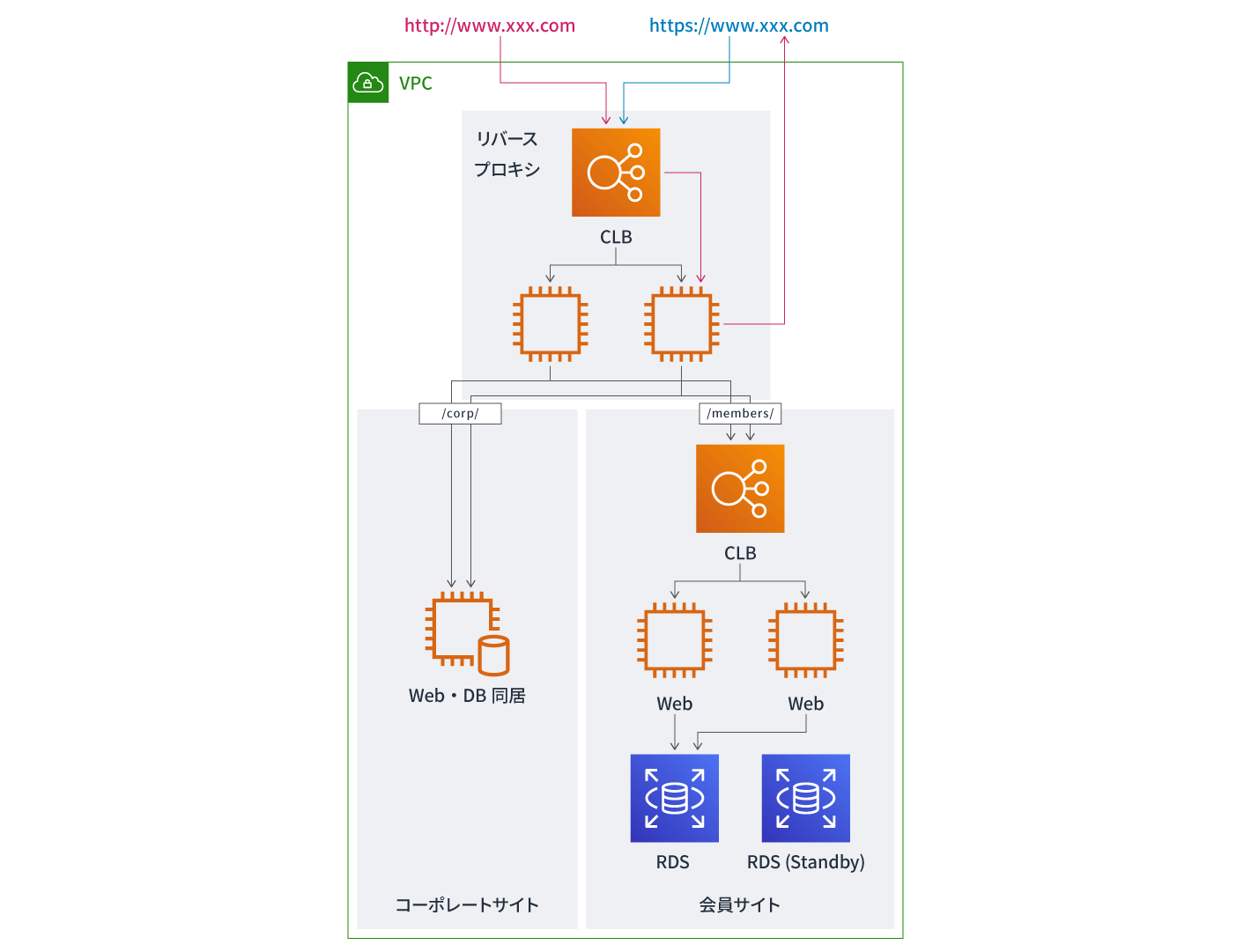
最適化の方法
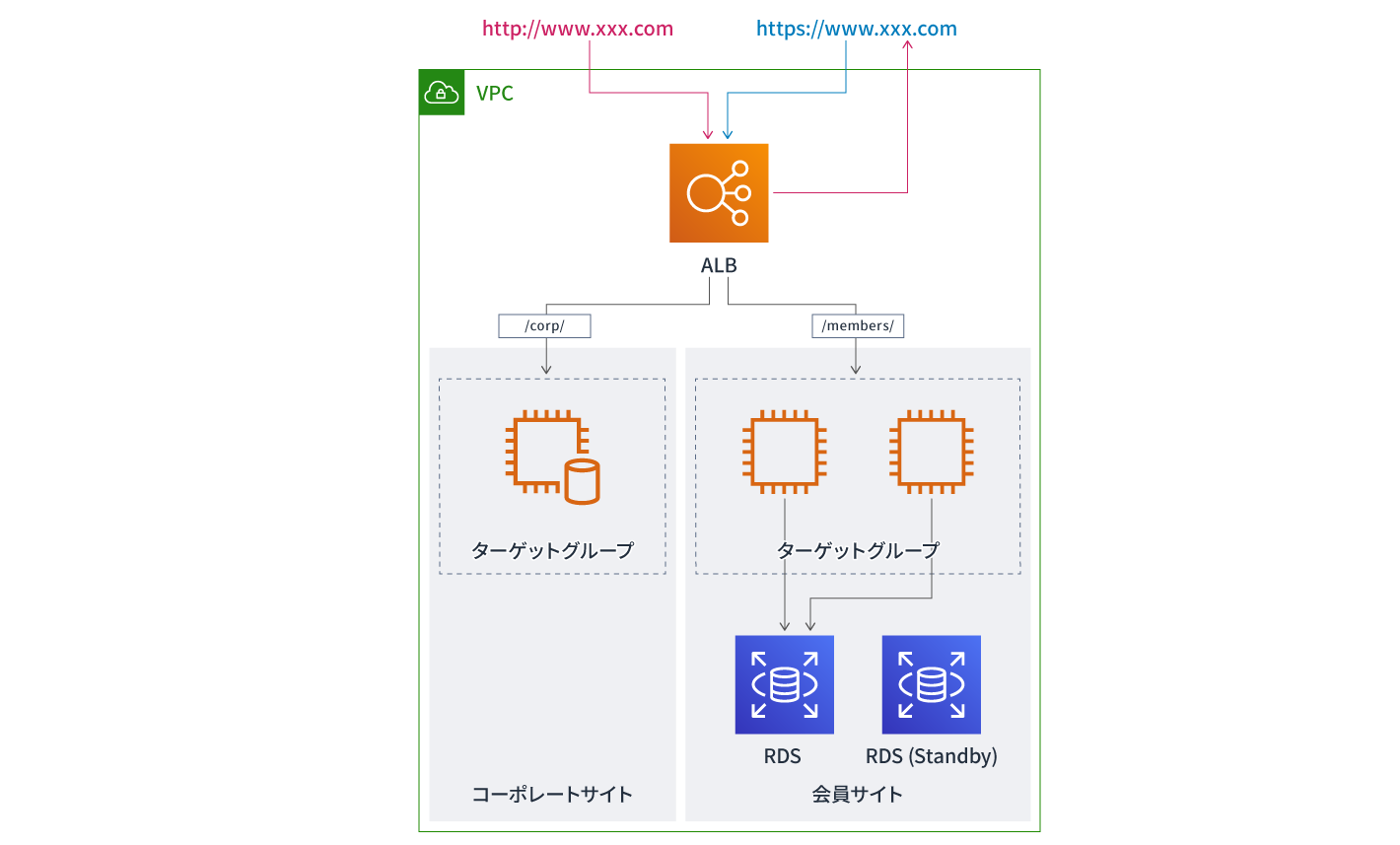
Application Load Balancer(ALB)でパスレベルでの振り分けを実装
この状況を解決するため、まずはマネージド型のL4ロードバランサーであるCLBを使い、リバースプロキシを立てることを検討しました。CLBはアベイラビリティーゾーンをまたいだ振り分けが可能で冗長化されているため、VIPの切り替えを意識しなくてもよいというメリットがあります。高負荷時には自動スケールができ、SSLの終端が可能です。CLBとリバースプロキシ2台を立てることで1つのFQDN内でウェブサイトを公開するかつ、リバースプロキシでHTTPからHTTPSへのリダイレクトを行う構成を考えました。
しかし、この構成だとEC2が増加してしまうため、AWS利用料も管理・運用コストも上がってしまいます。
そこで別案として浮上したのがApplication Load Balancer(ALB)を導入することです。ALBは2016年8月にリリースされたマネージド型のL7ロードバランサーで、高機能かつ機能が追加され続けていることが魅力のサービスです。2019年3月にはパスベース、ホストベースでのルーティングに加えHTTPヘッダーやクエリ文字列によるルーティングも可能になりました。HTTPからHTTPSへのリダイレクトやソーリーサイトのホスティングも可能で、SNIもサポートしており、一つのALBの中で複数のSSL管理もできます。
コーポレートサイトと会員サイトのインスタンスをターゲットグループで囲み、ALBでアクセスを受け、パスレベルでそれぞれのターゲットグループに振り分ける構成にすることで、要件を満たすことができました。
残課題と今後のシフト予定
コーポレートサイトがシングル構成のままになっているため、次のステップでは冗長構成にすることを検討しています。
また、ALBの例のように、AWS上のサービスは随時機能拡張されていくため、過去導入を検討した時の課題点も、いつの間にかクリアされているということがあります。そのため、既に知っているサービスであっても、仕様を適宜確認することが重要と言えます。
<ミズノ株式会社様 事例>AWS運用コストを3割削減した秘訣
事例3 ECサイトのログ・メトリックスの集約
シフト前の状況
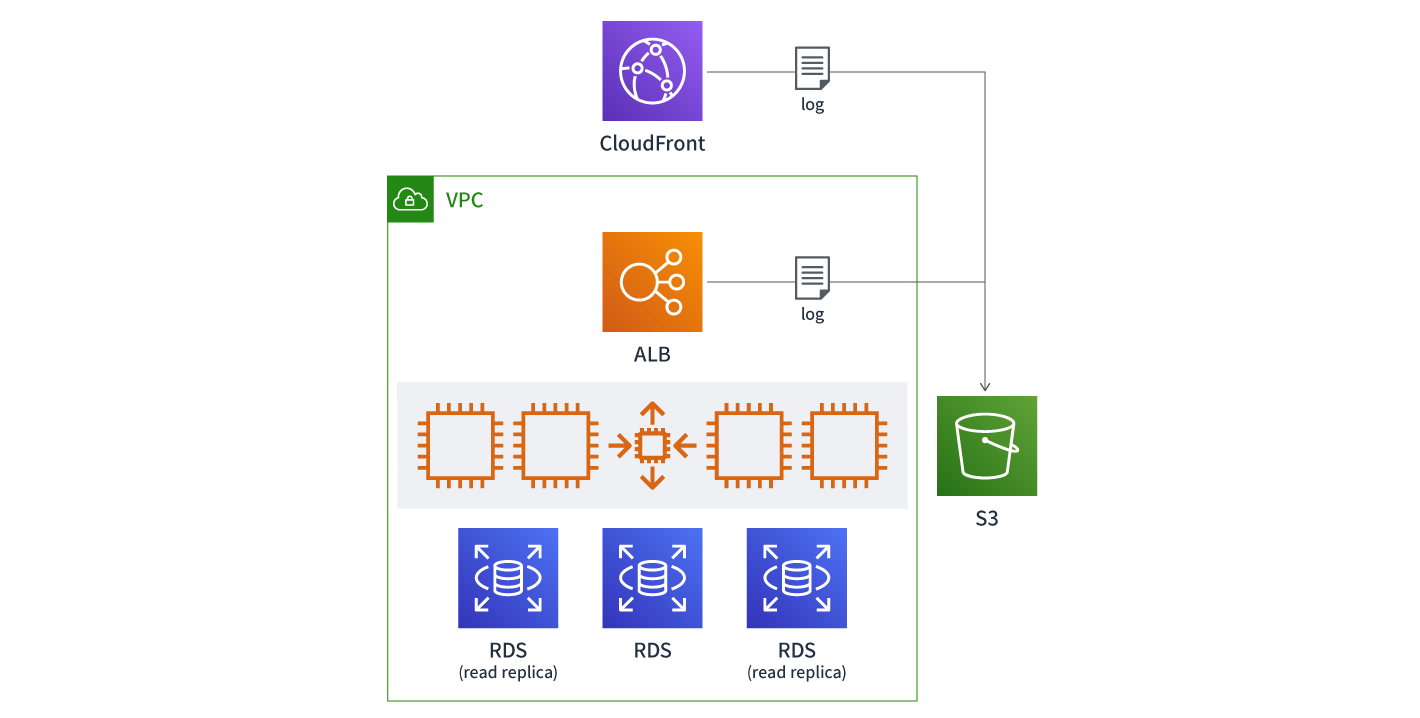
ECサイトをAWSで運営しているC社。AWSが提供するCDNサービスであるAmazon CloudFrontを導入し、静的ファイルのキャッシングを行っています。また、EC2のAuto Scalingも設定しており、インスタンス数の増減でアクセスの増減に対応をしています。なお、Amazon CloudFrontとALBのアクセスログはS3に収集しています。過去にデータベースのクエリ滞留がボトルネックとなっていたことがありますが、これは読み込み専用のレプリカ(リードレプリカ)をRDSで作成し、読み込みのクエリをリードレプリカに向けることで解消しました。
課題
EC2でヘルスチェックがNGとなり、ターミネートする事象が頻発するようになりました。監視サービスであるAmazon CloudWatchで状況を確認しましたが、標準メトリクスのCPU使用率は異常値を示していませんでした。ターミネートしたEC2インスタンスの詳細なメトリクスやログは設定をしていなかったため、原因の調査が出来ない状況になっていました。
既にAmazon CloudWatchを利用している方はご存知かと思いますが、Amazon CloudWatchでは特に設定を行わず標準で取得できるメトリクスが限られています。自身で設定をしなければ、メモリやディスクの使用率などが取得できないのです。
最適化の方法
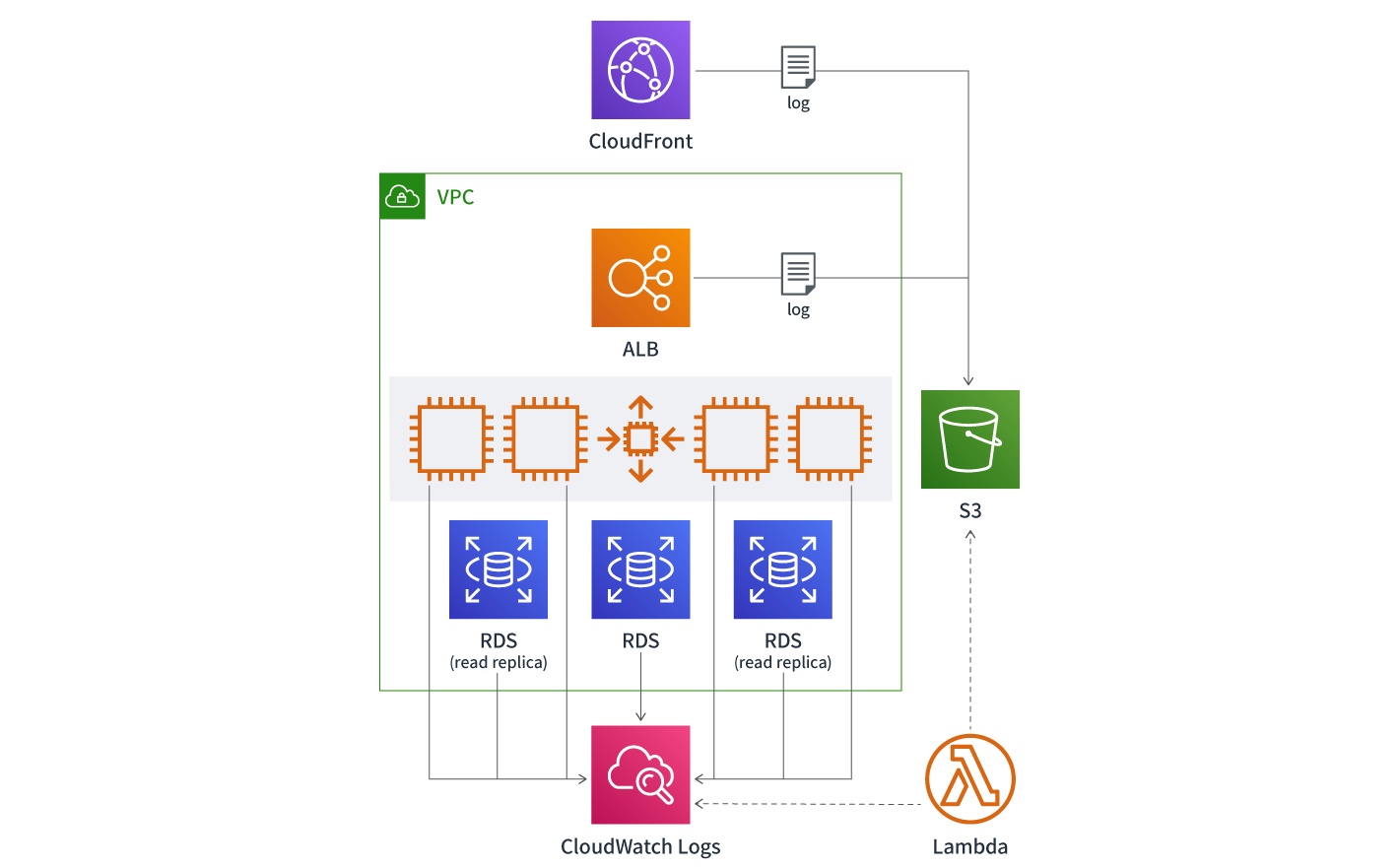
Amazon CloudWatch Logsにより取得するメトリクス数を増やし分析を強化
まずはAmazon CloudWatch Logsというマネージド型のログ管理ツールを導入することにしました。Amazon CloudWatch Logsでは、2017年12月よりログ収集とメモリやディスク使用率のメトリックスが取得できるCloudWatch エージェントが利用可能となっています。導入もエージェントのインストール後ウィザード形式の質問に回答するだけなので簡単です。
Amazon CloudWatch Logsの導入で取得できるメトリクスを増やした結果、今回のEC2がターミネートする事象は、メモリの枯渇が原因と判明しました。
メモリの枯渇は、EC2にユーザーの行動履歴を取得する機能があり、これがMaster DBに負荷を掛けているようでした。そこで、Master DBを拡張することで解消することができました。
残課題と今後のシフト予定
今後は、Amazon CloudWatch Logsに溜まっているログデータを定期的にS3へ蓄積し、解析基盤であるRedShiftにロードし、ユーザーの行動履歴を分析する機能を実装することを検討しています。
まとめ
AWS上でシステムを運用する上で重要な「最適化の継続」について3つの具体例をご紹介しました。ビジネスの要件が絶えず変化していると同時に、AWSのサービスも拡張しつづけています。そのため、移行したら終わりではなく、常に最適な状態を模索し続けることがAWS運用のポイントです。
「最適化の継続」には、自社が未評価のサービスや機能を評価できる「環境と文化」が必要です。出来る限り本番と同等のステージング環境を用意し、いつでも構成変更の評価ができる環境を整えること。そうした環境の中で、トレードオフの際に残課題としたものも、定期的にレビューする習慣をつけること。そして必要であればいつでも評価をしてもよいという文化と予算を用意すること。この3点を整えることが、最適なAWS環境の運用のために重要と言えるのではないでしょうか。
本記事が皆様のAWS運用の手助けになると幸いです。
連載「AWSに移行した環境の最適化のススメ」
【1】 AWSへの移行と障害時の対応
【2】 AWSへの最適化の考え方
▶【3】 事例と構成例
※本記事の内容につきましては2020年3月時点での情報です。
AWSの運用を最適化したい方にオススメ!

コストを3割削減した秘訣
MSP事業者に運用を任せっきりになっていたため、AWSの構成や設定・稼働状況などがブラックボックスに…。そんな状況の中、運用管理コストを最適化した方法をご紹介します。