
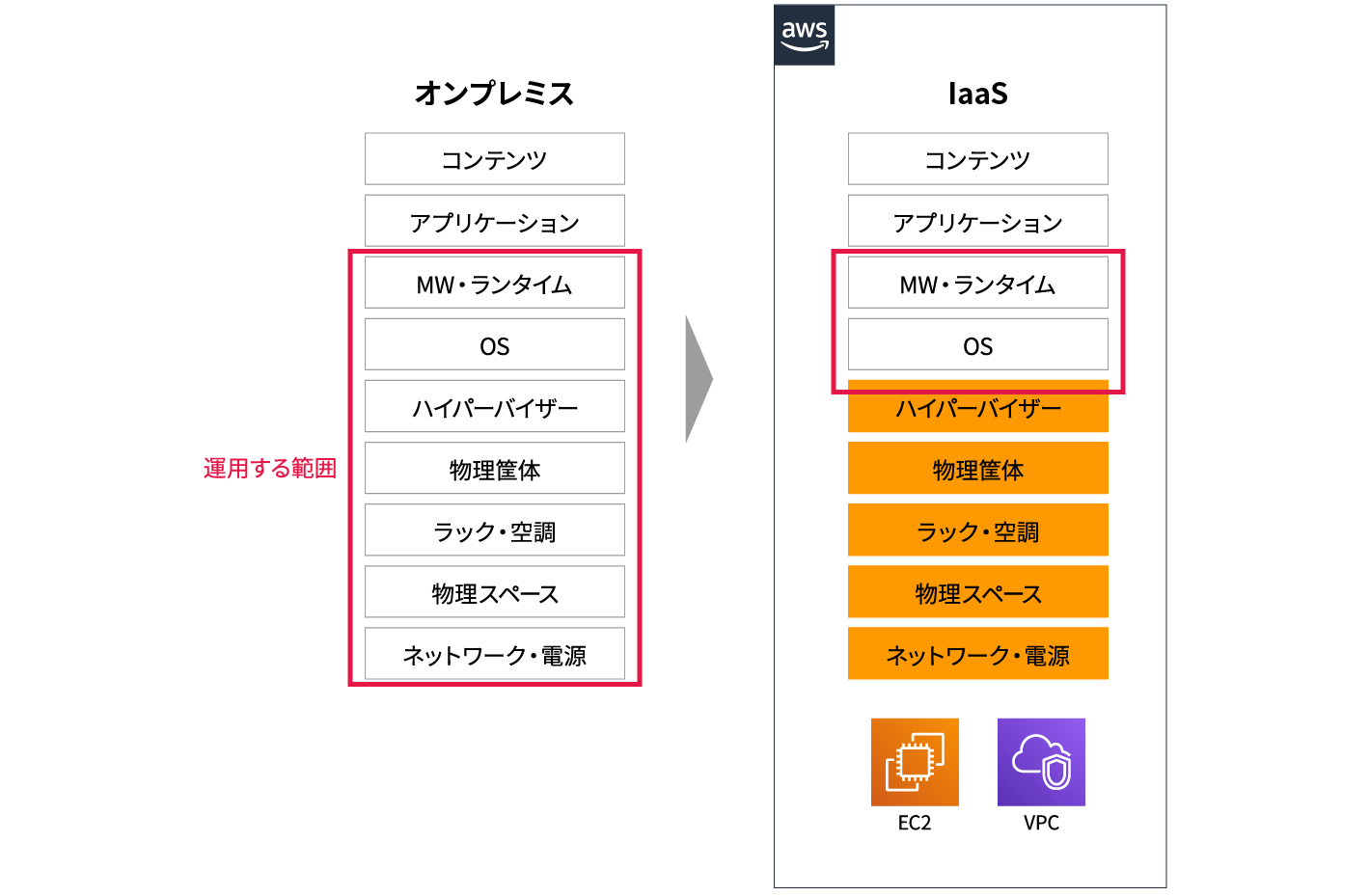
近年のクラウド化の流れを受け、システムのAWS移行を検討中の方も多いと思いますが、AWSへの移行後の運用についても検討されていますか? AWSに移行することで、物理的なサーバーの管理・保守は必要なくなりますが、AWSへの移行後もオンプレミスと同様にOSへのパッチ適用など物理レイヤー以上のインフラの運用は必要となります。
本連載記事では、AWSへシステムをオンプレミスの構成からあまり変更せずにリフトアンドシフト方式で移行したあとに必要な設計と運用を最適化させるための考え方や方法をご紹介します。
連載「AWSに移行した環境の最適化のススメ」
▶【1】 AWSへの移行と障害時の対応
【2】 AWSへの最適化の考え方
【3】 事例と構成例
AWSへの移行
システムやアプリケーションの移行を進める際に「どんなシステムを」「どこに」「どうやって移行するか」の3点を検討されると思います。移行先としてAWSを検討する場合、まずはAWSのサービスについて理解する必要があります。
AWSでは、IaaSやPaaSからSaaS/BaaS/FaaSのようなコンテンツやファンクションを載せるだけで稼働するようなサービスまで、多種多様なラインナップが用意されています。そのため、どんなサービスを、どのように組み合わせて構成するかなど、移行戦略を立てる上でしっかりと検討する必要があります。
はじめてクラウドを利用する際にはオンプレミスからAWSへ環境をそのまま移行するリフトアンドシフトがオススメです。リフトアンドシフトでは移行後にAWSへの環境最適化を行います。移行と最適化を別のフェーズで対応することができ、移行時のハードルと負担を下げることができます。
障害を予防するためのITインフラの運用設計
AWSへの移行後の設計や運用を考える前に知っておきたいことが、AWSでどのような障害が起きるのかです。
オンプレミスでもAWSでも変わらない考え方として、ITインフラの運用では「障害の検知」「障害からの復旧対応」「障害への恒久対策」の3つに関わる業務に多くの時間を割くため、設計段階では「障害の予防」が重要視されます。ただし現実的にはすべての障害を未然に防ぐことは不可能であり、障害発生時の影響範囲をいかに減らすかを考えながらITインフラの設計をする必要があります。
しかし、障害の影響範囲を減らすためには、サーバーやネットワーク機器の冗長化などの対策が必要であり、対策を実施すればするほどコストは増大します。つまり「障害の予防」と「コスト」はトレードオフの関係となっており、この妥協点をビジネスへの影響度から探ることがITインフラ運用を考慮した設計のポイントとなるのです。
AWSへ移行した段階で起こり得る障害とは?
よくお客様から「AWSに移行すればシステム障害は発生しなくなりますよね?」と聞かれます。結論から申し上げると、AWSでもオンプレミスと同様に、障害は発生します。ただし、AWSでは障害発生時の影響範囲を減らすための機能や選択肢が、いくつも用意されていることが大きな違いです。
AWSにシステムを移行したリフト段階で発生しうる障害としては、以下が挙げられます。
インスタンス障害
使用している仮想サーバーが正常に稼動しなくなることがあります。EC2の場合、インスタンスを停止して起動すると別のハードウェア上で立ち上がるという仕様になっているため、停止・起動を行うと正常には戻りますが、障害は発生するといえます。
アベイラビリティゾーン(AZ)間通信の一時的な遅延または瞬断に起因する障害
地理・電源・ネットワーク的に分離されているデータセンター群であるAZは高速専用線で接続されていますが、この通信が一時的に遅延・瞬断することがあります。
メンテナンス通知を見逃したことによる予期しない再起動
EC2にはハイパーバイザーのアップデート等の理由でメンテナンスが入ることがあります。このメンテナンスは、事前に期日までにインスタンスの再起動を実施してくださいという旨の通知があります。指定された期日までに、再起動をしないと自動的に再起動がかかります。そのため事前の通知を見逃してしまうと、意図しないタイミングで再起動が発生することになります。
アクセス急増に起因するメモリ枯渇
割り当てているメモリを使い切ってしまうとLinuxでいうところのOOM Killerが走って、プロセスがダウンすることがあります。
上記のような障害に対しては、ビジネスへの影響度を考慮した上で、AWSユーザー自ら対策を検討する必要があります。
AWS移行後の障害対応範囲
AWSでは主要なサービスおいて、個別にSLAを設定しています。中でもよく使われるサービスであるAmazon EC2では、2020年3月時点で99.0%以上99.99%未満であれば10%、99.0%未満の場合は30%のサービスクレジット(返金)が定義されています。ただしSLAには以下のとおり「例外となるケース」も定められています。
(i)AWS契約第 6.1 項に定めるサービス停止の結果である場合
(ii)不可抗力、対象製品およびサービスの責任分界点の範囲外のインターネットアクセスまたは関連する問題を含む、アマゾンの合理的な支配の及ばない要因により生じたものである場合
(iii)回復ボリュームを認識することを怠った場合を含む、サービス利用者または第三者の作為もしくは不作為の結果である場合
(iv)サービス利用者の機器、ソフトウェアもしくはその他の技術、および/または第三者の機器、ソフトウェアもしくはその他の技術(アマゾンの直接支配の範囲にある第三者の機器を除く)により生じたものである場合
(v)地域(Region)使用不能に帰因するものでない、個別のインスタンスまたはボリュームの障害の結果生じたものである場合
(vi)AWS 契約に従って規定されるメンテナンスの結果生じたものである場合、または
(vii)AWS契約に従って対象製品およびサービスを利用するサービス利用者の権利をアマゾンが停止もしくは終了させた結果である場合
上記の中で特に注目すべき点としては、(ii)(v)(vi)の3点です。簡単に言うと、AWSが直接的な要因でない場合、リージョン単位以外の障害である場合、AWSのメンテナンスによって生じた障害である場合は返金対象にならないと定められています。つまり、OSより上のレイヤーに起因する障害や、インスタンス障害、アベイラビリティゾーンの障害、計画メンテナンスによる意図しない再起動などはSLAの対象外となるのです。
そのためAWS移行後もこれらの障害が発生することを前提とした設計・運用を行う必要があります。
次回の記事では、AWSへの最適化の考え方についてより詳細に解説します。
連載「AWSに移行した環境の最適化のススメ」
▶【1】 AWSへの移行と障害時の対応
【2】 AWSへの最適化の考え方
【3】 事例と構成例
※本記事の内容につきましては2020年3月時点での情報です。
AWSの運用を最適化したい方にオススメ!

コストを3割削減した秘訣
MSP事業者に運用を任せっきりになっていたため、AWSの構成や設定・稼働状況などがブラックボックスに…。そんな状況の中、運用管理コストを最適化した方法をご紹介します。